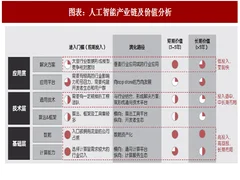
产业链根据技术层级从上到下分为基础层、技术层和应用层。基础层分为计算能力层与数据层,以 gpu、fpga、asic 和类脑芯片为代表的计算芯片位于计算能力层。此外还包括传感器、存储器、大数据和云计算进行基础支撑。
在这条产业链中,以硬件和数据为代表的基础层是构建生态的基础,价值最高,需要长期大量投入进行战略布局;通用技术层是构建技术壁垒的基础,投入适中,需要在中长期进行布局;而应用层直戳行业痛点,相对来说具有低投入变现快的特点。
不同环节不同需求,催生专用计算芯片。深度学习主要分为训练和推断两个环节:在数据训练(training)阶段,大量的标记或者未标记的数据被输入深度神经网络中进行训练,随着深度神经网络模型层数的增多,与之相对应的权重参数成倍的增长,从而对的计算能力有着越来越高的需求,此阶段(训练阶段)的设计目标是高并发高吞吐量;
推断(inference)则分为两大类——云侧推断与端侧推断,云侧推断推断不仅要求硬件有着高性能计算,更重要的是对于多指令数据的处理能力。就比如bing搜索引擎同时要对数以万计的图片搜索要求进行识别推断从而给出搜索结果;端侧推断更强调在高性能计算和低功耗中寻找一个平衡点,设计目标是低延时低功耗。
因此从目前市场需求来看,人工智能芯片可以分为三个类别:
用于训练(training)的芯片:主要面向各大ai企业及实验室的训练环节市场。目前被业内广泛接受的是“cpu gpu”的异构模式,由于 amd 在通用计算以及生态圈构建方面的长期缺位,导致了在深度学习 gpu 加速市场 nvidia 一家独大。面临这一局面,谷歌 2017年发布tpu 2.0能高效支持训练环节的深度网络加速。我们在此后进行具体分析;
用于云侧推断(inferenceoncloud)的芯片:在云端推断环节,gpu不再是最优的选择,取而代之的是,目前3a(阿里云、amazon、微软 azure)都纷纷探索“云服务器 fpga”模式替代传统 cpu 以支撑推断环节在云端的技术密集型任务。但是以谷歌tpu为代表的asic也对云端推断的市场份额有所希冀;
参考观研天下发布《》
用于端侧推断(inferenceondevice)的芯片:未来在相当一部分人工智能应用场景中,要求终端设备本身需要具备足够的推断计算能力,而显然当前 arm 等架构芯片的计算能力,并不能满足这些终端设备的本地深度神经网络推断,业界需要全新的低功耗异构芯片,赋予设备足够的算力去应对未来越发增多的人工智能应用场景。我们预计在这个领域的深度学习的执行将更多的依赖于 asic。

端侧 ai 芯片:soc ip 模式有望成为端侧主流。我们此前进行过介绍,未来在相当一部分人工智能应用场景中,要求终端设备本身需要具备足够的推断计算能力,而终端市场对芯片的功耗、面积、成本都有极为苛刻的要求。目前端侧人工智能芯片主要有独立asic和“soc ip”两种模式:
独立 asic:顾名思义,即研发设计、生产一款单独asic芯片用于深度神经网络加速,目前movidius的myriad系列芯片就是这种模式。其缺点在于开发周期长、投入成本大,一般公司难以承担;
“soc ip”模式:这一模式将深度神经网络加速做成 ip,作为一个模块加入soc。深度学习加速ip可以由专门公司开发、soc厂购买,也可以由 soc 厂自主开发。本质上与此前将 isp、dsp、 gpu等模块加入soc的历史类似,在成本、开发周期上具有极大优势,缺点则是功能拓展性有限;


我们认为“soc ip”模式有望成为主流。当深度神经网络加速功能做成 ip 时,它就成为 soc 的一个模块,当 soc 需要做深度学习相关运算时就交给该模块去做。因此对于深度学习加速领域的企业,能够更为灵活、更小投入地对深度学习加速产品进行开发和升级。近期发布的高通骁龙 835 与海思麒麟 970 均采用了这一模式。


目前,做深度学习加速ip的公司有ceva、cadence等等。这些公司的设计大多是基于已有的dsp架构,设计比较保守。也有如kneron的初创公司试图用全新的加速器架构设计来满足应用的需求。
在这条产业链中,以硬件和数据为代表的基础层是构建生态的基础,价值最高,需要长期大量投入进行战略布局;通用技术层是构建技术壁垒的基础,投入适中,需要在中长期进行布局;而应用层直戳行业痛点,相对来说具有低投入变现快的特点。
图表:人工智能产业链及价值分析
推断(inference)则分为两大类——云侧推断与端侧推断,云侧推断推断不仅要求硬件有着高性能计算,更重要的是对于多指令数据的处理能力。就比如bing搜索引擎同时要对数以万计的图片搜索要求进行识别推断从而给出搜索结果;端侧推断更强调在高性能计算和低功耗中寻找一个平衡点,设计目标是低延时低功耗。
因此从目前市场需求来看,人工智能芯片可以分为三个类别:
用于训练(training)的芯片:主要面向各大ai企业及实验室的训练环节市场。目前被业内广泛接受的是“cpu gpu”的异构模式,由于 amd 在通用计算以及生态圈构建方面的长期缺位,导致了在深度学习 gpu 加速市场 nvidia 一家独大。面临这一局面,谷歌 2017年发布tpu 2.0能高效支持训练环节的深度网络加速。我们在此后进行具体分析;
用于云侧推断(inferenceoncloud)的芯片:在云端推断环节,gpu不再是最优的选择,取而代之的是,目前3a(阿里云、amazon、微软 azure)都纷纷探索“云服务器 fpga”模式替代传统 cpu 以支撑推断环节在云端的技术密集型任务。但是以谷歌tpu为代表的asic也对云端推断的市场份额有所希冀;
参考观研天下发布《》
用于端侧推断(inferenceondevice)的芯片:未来在相当一部分人工智能应用场景中,要求终端设备本身需要具备足够的推断计算能力,而显然当前 arm 等架构芯片的计算能力,并不能满足这些终端设备的本地深度神经网络推断,业界需要全新的低功耗异构芯片,赋予设备足够的算力去应对未来越发增多的人工智能应用场景。我们预计在这个领域的深度学习的执行将更多的依赖于 asic。
图表:人工智能芯片生态体系
端侧 ai 芯片:soc ip 模式有望成为端侧主流。我们此前进行过介绍,未来在相当一部分人工智能应用场景中,要求终端设备本身需要具备足够的推断计算能力,而终端市场对芯片的功耗、面积、成本都有极为苛刻的要求。目前端侧人工智能芯片主要有独立asic和“soc ip”两种模式:
独立 asic:顾名思义,即研发设计、生产一款单独asic芯片用于深度神经网络加速,目前movidius的myriad系列芯片就是这种模式。其缺点在于开发周期长、投入成本大,一般公司难以承担;
“soc ip”模式:这一模式将深度神经网络加速做成 ip,作为一个模块加入soc。深度学习加速ip可以由专门公司开发、soc厂购买,也可以由 soc 厂自主开发。本质上与此前将 isp、dsp、 gpu等模块加入soc的历史类似,在成本、开发周期上具有极大优势,缺点则是功能拓展性有限;
图表:高通骁龙 835 具备 hexagon dsp 模块
图表:海思麒麟 970 加入神经网络处理模块
我们认为“soc ip”模式有望成为主流。当深度神经网络加速功能做成 ip 时,它就成为 soc 的一个模块,当 soc 需要做深度学习相关运算时就交给该模块去做。因此对于深度学习加速领域的企业,能够更为灵活、更小投入地对深度学习加速产品进行开发和升级。近期发布的高通骁龙 835 与海思麒麟 970 均采用了这一模式。
图表:海思 kirin 970 so c
图表:目前部分深度学习 ip 厂商
目前,做深度学习加速ip的公司有ceva、cadence等等。这些公司的设计大多是基于已有的dsp架构,设计比较保守。也有如kneron的初创公司试图用全新的加速器架构设计来满足应用的需求。
资料来源:观研天下整理,转载请注明出处(zq)
更多好文每日分享,欢迎关注公众号
【金沙下载送彩金的版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在金沙下载送彩金的版权问题,烦请提供金沙下载送彩金的版权疑问、身份证明、金沙下载送彩金的版权证明、金沙下载送彩金的联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。
